정렬
정렬이란?
💡 n개의 입력값이 주어졌을 때, 사용자가 지정한 기준에 맞게 정렬하여 출력하는 알고리즘
공통 문제
- 아래 문제를 모든 정렬방식으로 풀어볼 예정
- 문제 설명
- 주어진 N개의 수를 오름차순으로 정렬한 결과 출력
- 공통 코드
public class Main_2750수정렬2 {
public static void main(String[] args) throws IOException {
BufferedReader br = new BufferedReader(new InputStreamReader(System.in));
StringBuilder sb = new StringBuilder();
int N = Integer.parseInt(br.readLine());
int[] input = new int[N];
for(int i=0; i<N; i++){
input[i] = Integer.parseInt(br.readLine());
}
//정렬 함수 실행
//정렬 함수 실행 끝
//출력
for(int i=0; i<N; i++){
sb.append(input[i]).append("\n");
}
System.out.println(sb.toString());
}
}버블 정렬
개념
- 버블이 수면 위를 올라오듯, 옆에 있는 데이터와 비교하여 정렬하는 알고리즘
로직
- 맨 앞의 값부터 오른쪽에 있는 값과 비교하여 정렬(교환)
- 마지막 값까지 교환을 완료하면 가장 큰(작은) 값이 맨 뒤로 이동
- 맨 끝에 정렬된 값을 제외하고 위 과정을 반복(제외되는 값이 매회 하나씩 늘어남)
시간복잡도 : O(N^2)
- Worst, Average, Best 동일
- 선택, 삽입정렬과 시간복잡도가 같지만 연산 수가 많아 정렬 알고리즘 중 가장 느리고 효율성이 떨어지는 방법
코드
public static int[] bubbleSort(int[] input){
int last = input.length-1;
while(last>0){
for(int i=0; i<last; i++){
if(input[i]>input[i+1]){
swap(input, i, i+1);
}
}
last --;
}
return input;
}
public static void swap(int[] input, int idx1, int idx2){
int tmp = input[idx1];
input[idx1] = input[idx2];
input[idx2] = tmp;
}선택 정렬
개념
- 현재 위치에 들어갈 값을 찾아 정렬하는 방법
- 저장되어 있는 자료로부터 k번째로 큰 혹은 작은 원소를 찾는 방법
- 최소, 최대 혹은 중간 값을 찾는 알고리즘
로직
- 주어진 리스트 중 최솟값 찾기
- 그 값을 리스트 맨 앞에 위치한 값과 교환
- 맨 처음 위치를 제외한 나머지 리스트를 대상으로 위 과정 반복
- 최소 선택 정렬으로, 최대 선택의 경우 최댓값을 찾아 같은 과정을 반복하면 됨
시간복잡도 : O(N^2)
- Worst, Average, Best 동일
코드
public static void selectionSort(int[] input){
for(int i=0; i<input.length-1; i++){
int leastIdx = i;
//최솟값 찾기
for(int j=i+1; j<input.length; j++){
if(input[j]<input[leastIdx]){
leastIdx = j;
}
}
if(i!=leastIdx){
swap(input, i, leastIdx);
}
}
}
public static void swap(int[] input, int idx1, int idx2){
int tmp = input[idx1];
input[idx1] = input[idx2];
input[idx2] = tmp;
}삽입정렬
개념
- 현재 위치에에서, 그 이하의 배열들을 비교하여 자신이 들어갈 위치를 찾아 그 위치에 삽입하는 알고리즘
로직
- 첫번째 인덱스 값은 이미 정렬된 것으로 간주하여 두번째 인덱스부터 시작
- 왼쪽 값부터 비교하며 필요하다면 교환
- 왼쪽에 더 이상 숫자가 없을 때까지 해당 값 비교
- 위 과정을 다음 인덱스에도 동일하게 적용하여 반복
시간복잡도 : O(N^2)
- Worst, Average 동일
- 이미 정렬되어 있는 경우 O(N)
코드
public static void insertionSort(int[] input){
for(int i=1; i<input.length; i++){
int key = input[i];
int j= i-1;
while(j>=0 && key <input[j]){
input[j+1]=input[j];
j--;
}
input[j+1] = key;
}
}카운팅 정렬
개념
- 주어진 배열 값의 범위가 작은 경우, 빠른 속도로 정렬할 수 있는 알고리즘
- 최댓값과 입력 배열의 원소 값 개수를 누적합으로 구성한 배열로 정렬을 수행
로직
- 입력 배열의 최댓값+1을 크기로 갖는 카운팅 배열 생성
- 입력 배열의 원소 개수만큼 더해, 카운팅 배열을 누접합 배열로 만들기
- 입력배열과 누적합 배열을 이용해 정렬
시간복잡도 : O(N+K) (K는 입력 배열의 최댓값)
코드
병합 정렬
개념
- 분할정복 알고리즘 중 하나
- 분할, 정렬, 결합 순으로 진행
- 배열을 2개 이상의 부분 배열로 분할하고 부분 배열에서 정렬을 한 뒤 결합하여 다시 정렬을 진행하며, 데이터 배열 전체가 다시 결합되고 정렬되면서 종료됨.
- 분할
- 주어진 배열을 두 개의 동일한 크기의 부분 배열로 분할
- 정복
- 두 개의 부분 배열을 정렬
- 두 배열의 크기를 다시 나올 수 있다면 다시 분할 단계로, 재귀적 호출 진행
- 병합
- 두개의 정렬된 부분 배열을 병합하여 하나의 정렬된 배열로 만듦
- 두 부분 배열의 첫번째 요소부터 비교하여 작은 숫자를 병합된 배열에 차례대로 넣는 방식으로 진행
- 두 부분 배열의 모든 원소가 병합된 배열로 이동할 때까지 병합 반복
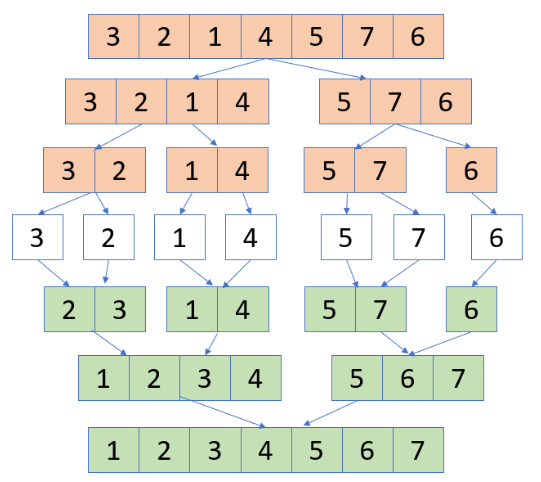
로직
- 주어진 배열의 크기가 2보다 크다면 분할(배열을 2개로 나눔)
- 좌측배열과 우측 배열의 분할을 재귀 호출로 반복
- 분할이 모두 끝나면 분할된 배열을 병합
- 병합할 때는 좌측 배열과 우측배열의 요소를 모두 비교하며, 좌측 배열이 더 클 때는 정렬할 배열 자리에 그 값을 넣고 좌측 배열 인덱스를 가리키는 변수 ++, 정렬 배열 인덱스 가리키는 변수 ++, 우측일 경우 우측 인덱스에 같은 방식 적용
- 좌측 배열, 우측 배열의 요소가 남아있는 경우 그 요소까지 모두 정렬 배열에 넣어줄 것
시간복잡도 : O(NlogN)
- Worst, Average, Best 모두 동일
- 항상 일정한 시간 복잡도를 유지해 퀵 정렬의 한계점을 보완
- 다른 알고리즘과 비교했을 때 O(N) 수준의 메모리가 추가로 필요하다는 단점
코드
static int[] sorted;
public static void mergeSort(int[] input, int left, int right){
sorted = new int[input.length];
//배열의 크기가 2보다 크다면
if(left<right){
int mid = (left+right)/2;
mergeSort(input, left, mid);
mergeSort(input, mid+1, right);
merge(input, left, mid, right);
}
}
public static void merge(int[] input, int left, int mid, int right){
int l = left;
int m = mid +1;
int idx = left;
while(l<=mid && m<=right){
if(input[l]<=input[m]){
sorted[idx++] = input[l++];
}else{
sorted[idx++] = input[m++];
}
}
//오른쪽 배열에 남아 있는 값이 있다면(왼쪽배열을 다 썼다면)
// 다 sorted에 넣기
if(l>mid){
for(int i=m; i<=right; i++){
sorted[idx++] = input[i];
}
}else{
for(int i=l; i<=mid; i++){
sorted[idx++] = input[i];
}
}
for(int i=left; i<=right; i++){
input[i]= sorted[i];
}
}힙 정렬
개념
- 힙
- 완전 이진트리의 일종으로 우선순위 큐를 위하여 만들어진 자료구조
- 이진트리란?
- 모든 노드의 자식 노드가 2개 이하인 트리 구조
- 완전 이진트리란?
- 데이터가 루트 노드부터 시작해서 자식 노드가 왼쪽 자식 노드, 오른쪽 자식 노드로 차근차근 들어가는 구조의 이진 트리
- 이진트리란?
- 최대힙은 부모 노드의 값이 자식 노드보다 커야 함
- 최댓값, 최솟값을 쉽게 추출할 수 있는 자료 구조
- 완전 이진트리의 일종으로 우선순위 큐를 위하여 만들어진 자료구조
- 힙 자료구조를 응용한 정렬 알고리즘
- 힙 생성 알고리즘(Heapify Algorithm)
- 특정 ‘하나의 노드’에 대해서만 수행
- 하나의 노드를 제외하고 최대 힙이 구성되어 있는 상태를 가정
- 특정한 노드의 두 자식 중에서 더 큰 자식과 자신의 위치를 바꾸는 알고리즘
- 시간복잡도 : O(logN)
- Heap Sort에서 사용하는 힙 생성 과정은 주어진 배열을 차례대로 삽입하지 않고 전체 배열을 한번에
로직
- 상향식 힙 구조 만들기
- 배열에 노드 숫자들을 넣음
- N/2만큼만 확인하면 됨
- 절반에 해당되는 값 중 가장 아래 값부터 Heapify 알고리즘 수행
- 하향식 힙 구조 만들기
- 특정 정점에서 시작해서 아래쪽으로 내려가면서 비교하는 것
- 힙 구조를 만든 후, 루트 노드부터 가장 큰 값이 있으므로 그 값을 가장 뒤에 있는 값과 자리 바꿔주기
- 자리를 바꾼 후에 루트 노드를 자식 노드와 비교하며 Heapyfy 수행
- 수행 후 루트 노드와 이전에 바꿔준 노드 앞자리의 노드의 값과 자리 바꿔주기
- 위 과정을 반복
시간복잡도 : O(NlogN)
- Worst, Average, Best 모두 동일
- 완전 이진트리 사용
코드
public static void heapSort(int[] input){
//트리구조를 최대 힙 구조로 바꾸기
for(int i=1; i<input.length; i++){
int c = i;
do{
int root = (c-1) /2;
if(input[root]<input[c]){
swap(input, root, c);
}
c = root;
}while(c!=0)
}
//크기를 줄여가며 반복적으로 힙을 구성
for(int i= input.length -1; i>=0; i--){
//가장 큰 값을 맨 뒤로 보내기
swap(input, 0, i);
int root = 0;
int c=1;
//힙 구조 만들기
do{
c = 2*root+1;
if(c<i-1 && input[c] < input[c+1] ){
c++;
}
if(c<i && input[root] < input[c]){
swap(input, root, c);
}
root =c;
}while(c<i);
}
}
public static void swap(int[] input, int idx1, int idx2){
int tmp = input[idx1];
input[idx1] = input[idx2];
input[idx2] = tmp;
}
퀵 정렬
개념
- 데이터 중 임의의 기준 값을 정해 두 부분집합으로 나누어 더 이상 집합을 나눌 수 없을 때까지 재귀적으로 실행하는 알고리즘
- 배열에서 피벗(Pivot)을 선택하고, 피벗을 기준으로 파티션(Partition)을 나누어 배열을 정렬하는 방식
로직
- 피벗 선택(Pivot Selection)
- 피벗 선택방법은 여러가지가 있으며, 이에 따라 알고리즘의 성능이 달라지기도 함
- 분할(Partition)
- 선택한 피벗을 기준으로 배열을 두 개의 부분 배열로 분할
- 피벗보다 작거나 같은 원소들은 좌측에, 피벗보다 큰 원소들은 우측 부분배열에 위치
- 정복(Conquer)
- 두 개의 부분배열을 재귀적으로 호출하며 부분 배열의 크기가 0 또는 1이 될 때까지 반복
⇒위 방법으로 코드 구현한다면, 코드 로직은?
- 배열 입력이 주어졌을 때, 그 배열의 크기가 1보다 크면 그 배열을 분할하여 pivot 구하기
- 배열을 분할
- pivot을 기준으로 pivot보다 작은 값들은 좌측으로 이동
- pivot을 좌측 배열의 마지막 요소로 이동
- 배열 분할 후 반환된 pivot값을 기준으로 quick sort 재귀호출로 분할된 배열에 대하여 다시 분할 반복
시간복잡도 : O(NlogN)
- Average와 Best는 동일
- Worst : O(N^2)
- 이미 정렬된 데이터라면 매우 비효율적으로 작동
코드
public static void quickSort(int[] input, int left, int right){
if(left<right){
int pivot = partition(input, left, right);
quickSort(input, left, pivot-1);
quickSort(input, pivot+1, right);
}
}
public static int partition(int[] input, int left, int right){
int pivot = input[right];
int i = left -1;
for(int j=left; j<right; j++){
if(input[j]<=pivot){
i++;
swap(input, i, j);
}
}
swap(input, i+1, right);
return i+1;
}
public static void swap(int[] input, int idx1, int idx2){
int tmp = input[idx1];
input[idx1] = input[idx2];
input[idx2] = tmp;
}
}비교

'Learning-log -CS > Data Structure & Algorithm' 카테고리의 다른 글
| 알고리즘 - 조합 (0) | 2023.03.26 |
|---|---|
| 알고리즘 - 부분집합 (0) | 2023.03.26 |
| 자료구조 - 큐(Queue), 데크(Deque) (1) | 2022.11.24 |
| 자료구조 - 순차적 자료구조 : 스택(Stack)(2022.09.22~10.12) (0) | 2022.10.12 |
| 자료구조-순차적 자료구조 : 배열, 리스트(2022.09.21) (0) | 2022.09.24 |

